Experimenting with LLMs for Optical Character Recognition

This digital preservation project started some years ago now but was paused due to other commitments. Recently though I’ve had time to get back to work on it and this time bring some state-of-the-art tools to the job, namely LLMs – Large Language Models.
When this project first started publicly accessible LLMs weren’t particularly powerful and, in general, many couldn’t process images. Google’s OCR API at the time fell short as the built-in post-processing often attempted to change the printed spellings to modern ones but preservation of the original text is needed for this project. LLMs are now much more capable and revisiting them has yielded positive results.
Current work is on the English language version of the Bangkok Recorder, published from 1865-1867 by Dr D.B. Bradley and edited by Dr N.A. McDonald, both American Protestant missionaries. The paper covers local and regional news plus regular reports of the latter stages of the American Civil War and journals of expeditions to regions unchartered (by foreigners) in Siam. Their diary of a trip from Bangkok to Chiang Mai is so different from experience of the modern-day tourist trail!
For this comparison, the leading open source OCR program, Tesseract, will be compared to OpenAI’s gpt-4o model. A simple prompt is used to instruct the LLM:
Read this text. Preserve the line lengths and spaces between words. Do not correct spellings.
Test 1: Standard font size

Tesseract:
We had hoped to be able to have
‘the Recorder make its re-appear-
ance among the eitizens of Bang-
kok- at the first of the year, so
that it might wish them the com-
LLM:
We had hoped to be able to have
the Recorder make its re-appear-
ance among the citizens of Bang-
kok at the first of the year, so
that it might wish them the com-
Tesseract misinterprets page markings as characters, for example, the start of the second line, and misspells one word (citizens, 3rd line) but otherwise does a good job.
However, the LLM improves on this with perfect spelling, ignoring the page markings and indenting the paragraph.
Test 2: Small font, some unclear text
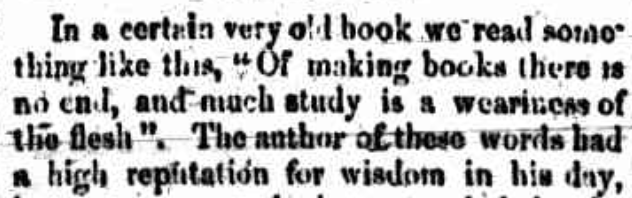
Tesseract:
In a certein very a! hook wo read somos
thing like thia, “Of making books there 1s
nd cad, and-mach study is a weariness of
‘le flesh. The anthor ofthese words had
a high repfitatién for wisdom in hie day,
LLM:
In a certain very old book we read some-
thing like this, “Of making books there is
no end, and much study is a weariness of
the flesh”. The author of these words had
a high reputation for wisdom in his day,
Tesseract starts to struggle here, returning garbled text.
The LLM isn’t confused though and represents the text perfectly, although omitting the paragraph indentation this time.
Test 3: Smallest font, faded text

Tesseract:
There vw he pronchingin the Daghsh lnez age
prota Beaty at & ew, in the Cvew Protestant
Choeel si, ivauked upea the eleer ba ©, adjeisiay it
Premed 0 tae Doewo Cospasy Lainie
Kote & ia,
Ui ire cordiallyiayite 1 ta atteod
LLM:
There will be preaching in the English language
every Sabbath at 4 P. M., in the New Protestant
Chapel situated upon the river bank, adjoining the
premises of the Borneo Company Limited, and
J. G. & Co.
All are cordially invited to attend
This text is unclear to the human eye and is clearly beyond the capability of Tesseract.
The LLM does an excellent job, reproducing the text almost perfectly, except for the paragraph indentation and one transcription mistake that is easily not noticeable from this one example alone – the fifth line should read J. Gunn & Co. instead of J. G. & Co. This is only known because the same text is repeated in other editions and many of them are much clearer to read, as in this example:

Test 4: Medium font, Thai language
Although the English version of the Bangkok Recorder is primarily in English, there are some pages in Thai, particularly in the earlier editions.

Tesseract:
9 แนงมีศเคซีโมร ก็ได้เปนเจ้ เข้
เมื่อง นุย8ก ได้สาม ยี้ ยมา แล้ว นั้น, รา
เข้เควัยฝ่าย พวกขยก+ ทํา การ ซักๆข้ง
ยู่ริศเต็ต์ลินกัล ต่าง ๆ นั้น’ ซาว เมือง
LLM:
⃝ อนึ่งมีศเตอร์ซีโมเว, ที่ได้เปนเจ้า
เมืองนุยอกไต้สามปี๋มาแล้วนั้น, มีใจ
เช่นควัยฝ่ายพวกขบถ, ทำการขัดขวาง
บริศเต็นศ์ลินกัลต่าง ๆ นั้น; ชาวเมือง
Actual:
๏ หนึ่ง มีศเตอ ซีโมร, ที่ ได้ เปน เจ้า
เมือง นุยอก ได้ สาม ปี มา แล้ว นั้น, มี ใจ
เช่น ดวัย ฝ่าย พวก ขบถ, ทำ การ ขัด ชอ้ง
ปริศเต็นต์ ลินกัล ต่าง ๆ นั้น; ชาว เมือง
Although it’s quite good, the LLM is struggling more. Here are several of the inaccuracies:
- Punctuation: in the first line the obsolete ๏ (ฟองมัน) is misrepresented as a circle character.
- English transliteration: ซีโมเว (“Seymowe”) instead of ซีโมร (Seymour), บริศเต็นศ์ (“Bresidens”) instead of ปริศเต็นต์ (President)
- Thai words: second line, ไต้ (tai) instead of ได้ (dai).
- Spaces between words aren’t preserved. This word spacing is specific to Bradley’s printing though and rarely found in any other Thai print, so it’s not surprising that the LLM doesn’t preserve it.
It should be noted that where it does read accurately it does maintain some archaic spellings. For example, on the first line เปน instead the modern day เป็น which became the common spelling in the mid-20th century. It also attempts to read ดว้ย (modern day ด้วย) with the ้ tone mark above the second letter, ว, instead of the first letter, ด. It unfortunately misreads both ั instead of ้ and ค instead of ด. However, preserving the archaic spellings is something Google OCR struggles with too, typically trying to auto-correct to modern equivalents.
Hallucinations
A hallucination is a “is a response generated by AI that contains false or misleading information presented as fact”. From the many pages processed so far from these newspapers, hallucinations are found quite frequently.
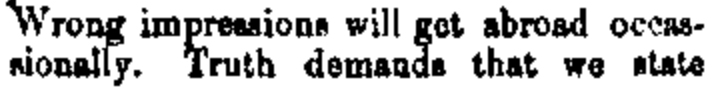
Wrong impressions will get abroad occa-
ssionally. Truth demands that we state
The hyphenation of “occassionally” is printed between the two Ss but the LLM decides to put them both on the second line. Of course, this doesn’t change the meaning at all, just the typography.
However, the next example is more problematic.
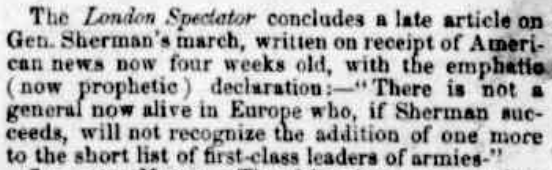
The London Spectator concludes a late article on
Gen. Sherman’s march, written on receipt of Ameri-
can news now four weeks old, with the emphatic
(now prophetic) declaration: – “There is not a
court nor office in Europe who, if Sherman suc-
ceeds, will not recognize the addition of one more
to the short list of first-class leaders of armies.”
The phrase “court nor office” is not in the original text. The LLM just made it up and, arguably, it fits the context somewhat.
Compare this with traditional OCR software as-in in test 3 above. When tesseract can’t read some text it’s obvious:
There vw he pronchingin the Daghsh lnez age
instead of the actual text:
There will be preaching in the English language
It’s easy to automate detection of these OCR failures with a simple n-gram analysis and then highlight to the user the lines most likely to need proofreadering and correction. However, LLMs can hallucinate perfectly reasonable text making it nearly impossible to detect, and instead requiring manual proofreading of all output.
Conclusion & Next Steps
Although the LLM isn’t flawless, it significantly outperforms Tesseract. Clearer text produces significantly better results, as would be expected, and Thai text is mostly read correct, although with more inaccuracies than English.
The next step is to improve the output quality. This will require fine-tuning of the LLM model. Training is on pairs of original and corrected line pairs will help teach it the desired output. Initially this will be done for the English newspaper as, at the time of writing, over 13,000 lines of text have already been manually proofread and corrected.
Recent reports of similar work from the University of Sheffield shows a >50% error reduction rate from just this basic training, based their work on 19th century English newspapers.
This project aims to publish online a first batch of the English language Bangkok Recorder newspapers (January - June 1865) within the next few months.